Playing Atari with Deep Reinforcement Learning
Playing Atari with Deep Reinforcement Learning
Background
Could AI learn to control itself with the raw input from the environment, rather than receiving the hand-crafted features. In this article, the authors introduced an approach which combines reinforcement learning and deep neural network. This new deep learning model demonstrates its ability to master different control policies for different Atari 2600 games with only raw pixel input.
Reinforcement Learning
Future reward and its Bellman’s expression:
The optimal action-value function: This means the maximum expected return achievable, after seeing some sequence $s$ and then taking some action $a$ and by following policy $\pi$, which mapping sequence to actions.
The $Q^{}(s,a)$ could be expressed using Bellman’s equation: However, $Q^{}(s,a)$ is an optimal value. Normally, people use using the Bellman equation as an iterative update to converge to the optimal action-value function, when $Q_{i}\rightarrow Q^{*} $ as $i \rightarrow \infty $.
In this article, a neural network is used as a non-linear approximator to estimate the action-value function, $Q(s,a;\theta )\approx Q^{*}(s,a)$, where $\theta$ stands for the weights. The loss function could be decribed as follows: , where $y_{i}=\mathbb{E}{ {s}’\sim \varepsilon }[r+\gamma max{ {a}’}Q_{i}({s}’,{a}’;\theta_{i-1})|s,a]$ and $\rho(s,a)$ is a probability distribution over sequences $s$ and actions $a$.
$\epsilon $-greedy
The next action is selected using $\epsilon $-greedy strategy.
Algorithm

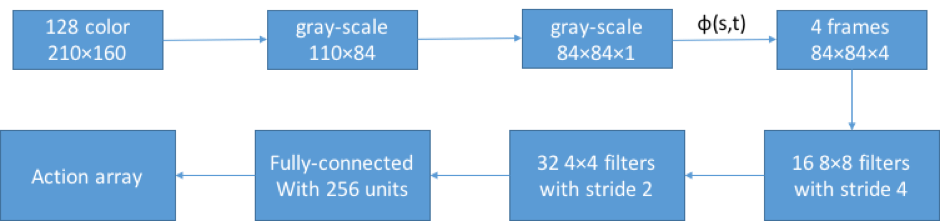
Architecture
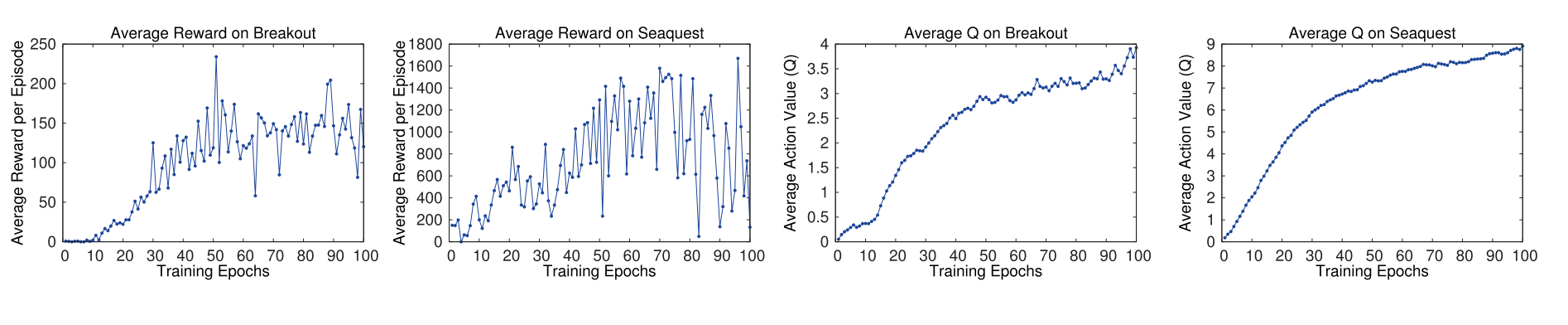
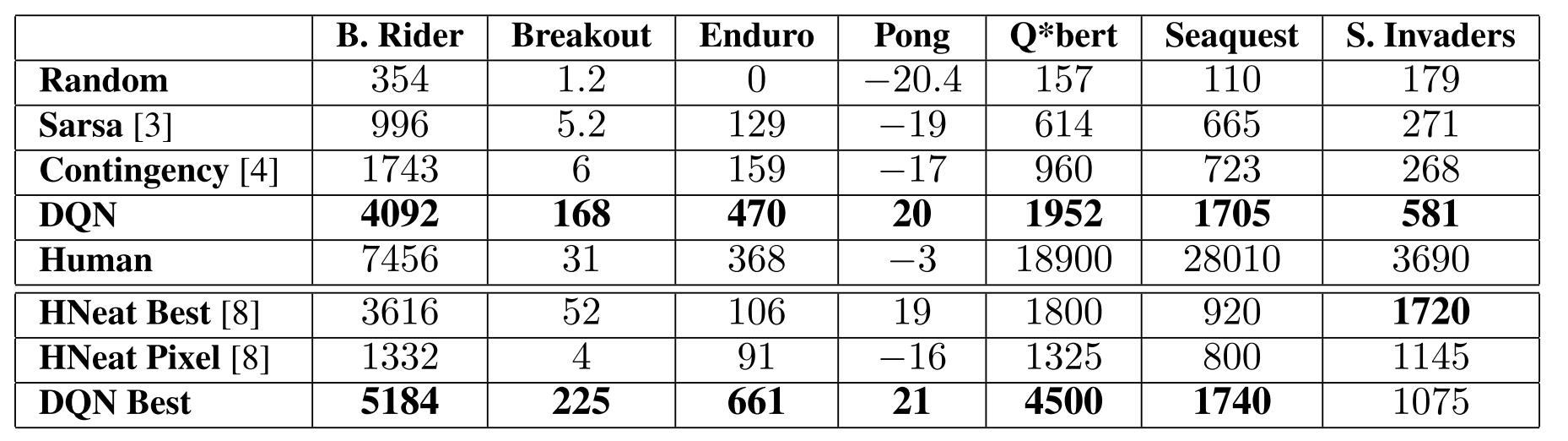
Experiment and Results